Compaction is the wrong abstraction
We ran a single agent session through 89 sequential tasks of Terminal Bench 2.0 and 80 million tokens with no measurable accuracy loss compared to per-task isolated sessions. The mechanism that made this possible is one we think the field has been avoiding: deterministic, model-free eviction guided by structure the agent declares as it works.
This post is about why we think summarization-based compaction is the wrong default, what we built instead, and where the design is honest about its costs. The full paper can be read at Here; this is the short version aimed at people who are themselves building agent harnesses and have opinions about context management.
The paper implementation is also open source and can be found in our repository Here
Compaction uses a model called to fix model calls
Compaction is a model call invoked to fix a problem caused by model calls. When the context approaches its limit, the agent is paused, the transcript is handed to an LLM with instructions to summarize it, and the summary replaces the original history. It's now the default in several widely used agent frameworks.
We think this is a mistake, and that the field has settled for it because it's structurally easy rather than because it's right. The main four issues we identify in the traditional compaction approach are:
- Lossiness is unpredictable. What the summarizer keeps and drops depends on its instantaneous judgment of salience, which is not the same as what the downstream agent will actually need to continue its work after compaction. The errors are invisible from the compacted context alone — there's no way for the agent to know what was thrown away.
- Structure is not preserved. The original trajectory has explicit causal structure made of tool calls, agent reasoning blocks, file reads, and executed bash commands and their outputs. Prose summaries collapse this into narrative and erase the provenance the agent would need to revisit its own reasoning.
- Compression is expensive and blocking. A compaction pass is a full LLM call over a large slice of the context window, paid in seconds of latency and tokens-in-tokens-out.
- Hallucinations are introduced at the worst moment. Summarization under length pressure is a known LLM failure mode. Specifically, models tend to understate errors and issues encountered by the agent in their summaries.
The agent is the cheapest annotator you'll find
To understand our approach, we first need to understand that the agent is in the best possible position to mark structure in its own trajectory as work proceeds. At the moment of doing the work it can cheaply distinguish between gathering information and acting on it, and it can cheaply note which prior information is used for the action being done right now. Those two cheap annotations are enough.
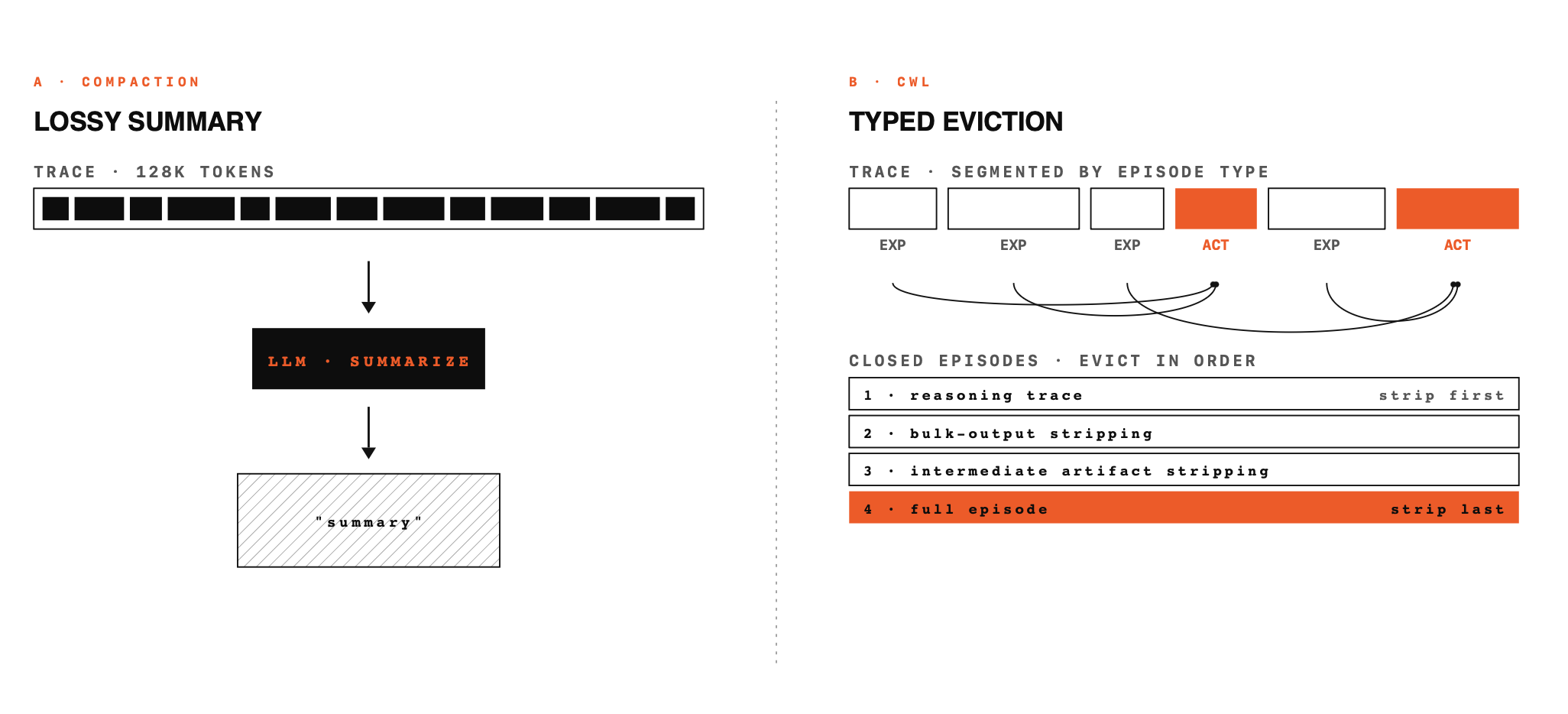
Context Window Lifecycle (CWL) uses them. The agent annotates its trajectory through a single tool, delimiter, marking episode boundaries and declaring dependencies between them. The annotations accumulate into a typed dependency graph. When token accounting reports the budget has been exceeded, a deterministic policy walks that graph and evicts content in priority order.
There are two episode types:
Exploratory episodes are where the agent gathers information — search results, file reads, directory listings, retrieved documents. These episodes carry the substantive content the agent reasons over. They are the information layer of the trajectory.
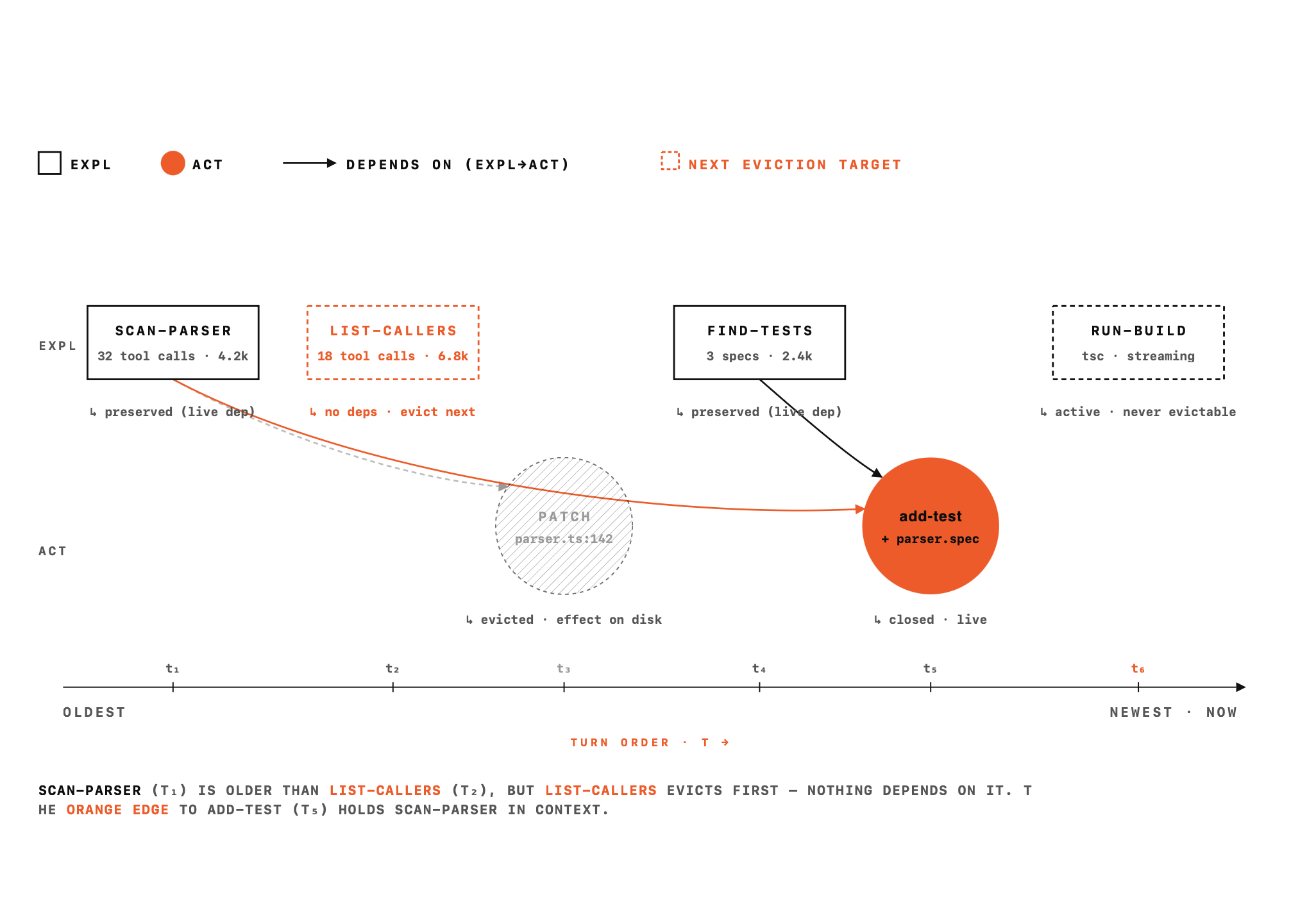
Action episodes are where the agent does work — edits, writes, tool calls that change the environment. Their content in the transcript is thin: the substantive information lives in the exploratory episodes they depend on, and the effects of the action live in the environment, not in context.
When opening an action episode, the agent declares which exploratory episode(s) it's drawing on. This is the dependency edge, and it's what makes the eviction policy semantically aware rather than just temporally ordered.
In practice the agent's calls look like this:
// Opening an exploratory episode — agent is about to gather information
{ "action": "start", "name": "locate-auth-middleware", "type": "expl" }
// ... tool calls happen here: grep, file reads, directory listings ...
// Closing it — description is the residue kept after full eviction
{ "action": "end",
"description": "Auth lives in src/middleware/auth.ts; uses JWT via jose; token claims validated in verifyToken() at line 47." }
// Opening an action episode — must declare which exploration it depends on
{ "action": "start",
"name": "add-refresh-token-rotation",
"type": "act",
"dependencies": ["locate-auth-middleware"] }
// ... tool calls happen here: file edits, bash commands ...
// Closing it — no description, since the effects live on disk, not in context
{ "action": "end" }The eviction policy is a loop. It walks the dependency graph and selects the oldest eligible action episode first, because action episodes carry little information of their own — their content is mostly a record of edits that are already reflected on disk and reconstructible by inspecting the environment. Exploratory episodes are evicted only after the action episodes that depended on them have themselves been evicted. Otherwise the agent would have a decision in context with no access to the reasoning behind it.
Within a selected episode, content is stripped in a specific order, from least to most informative:
- Reasoning traces first. Extended chain-of-thought is often a small fraction of the episode's tokens, and its conclusions are by construction reflected in the tool calls that follow it.
- Bulk search outputs next — grep, glob, ls, directory listings. These are the noisiest content in the trajectory: the agent was scanning through them looking for something specific, and most of what they returned was never used and can be quickly re-acquired.
- Intermediate artifacts after that — file reads, bash commands and their outputs. These carry real signal the agent actually wanted, so they go later.
- Full episode removal as the last resort.
User turns are never touched.
Capping active token count overtakes KV cache
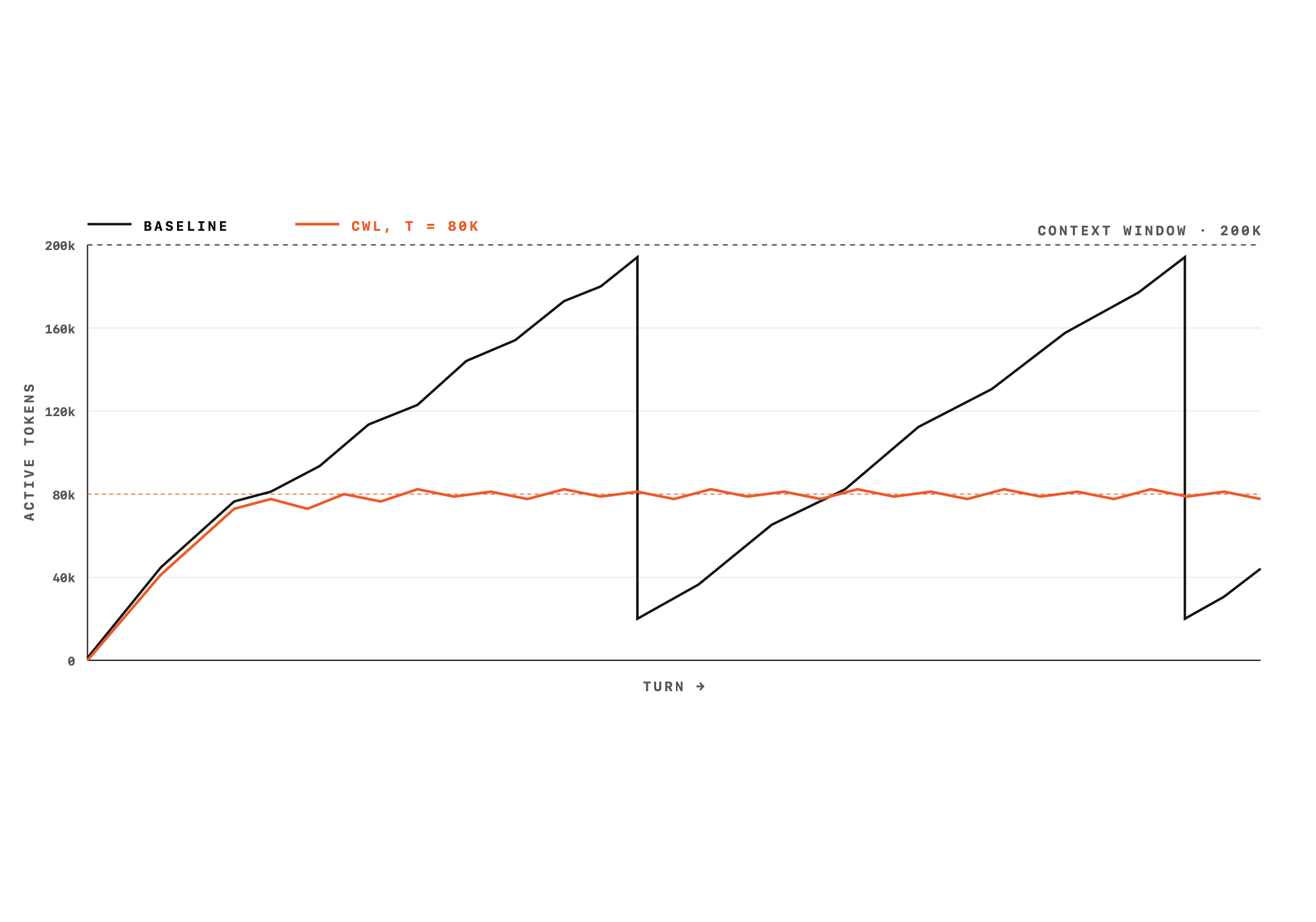
The result that surprised us most was with the KV cache behavior. We expected a sharp cost increase due to frequent cache invalidation. But in reality it's a little more than that.
At first pass, CWL looks worse for caching than compaction. CWL removes, modifies, and re-orders context with no respect to prefix preservation. Over long context windows (150,000+ tokens) this did amplify inference costs a lot.
The fix is a hard cap on the active token count, well below the model's actual context window. We define an active token budget τ and cap it at 80,000 tokens — about 30% of the window of the models we evaluated - gpt-5.4. Because eviction keeps the active count stable near this ceiling rather than letting it grow toward the full window, inference cost is almost unchanged compared to the baseline. New content enters at the tail, and an approximately equal volume is evicted at the head (or in between). As proven by the benchmark results, such a token cap does not degrade the model's performance.
What the numbers look like
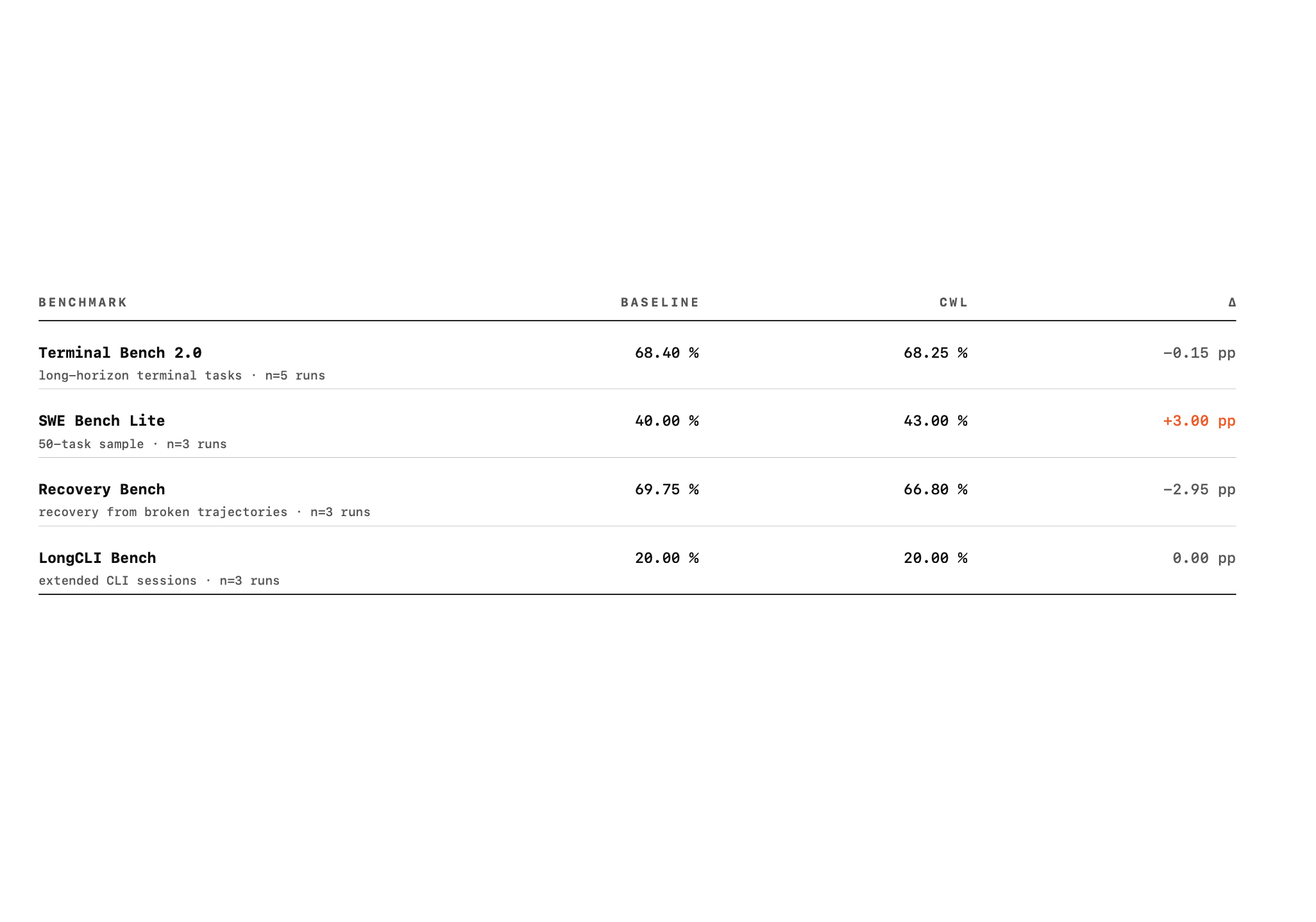
We evaluated on Terminal Bench 2.0 (89 tasks, n=5 runs), SWE Bench Lite (50-task sample, n=3), Recovery Bench (n=3), and LongCLI Bench (n=3). The CWL condition runs all tasks of a benchmark sequentially in a single uninterrupted session. The baseline runs each task in a fresh isolated session — the standard protocol for these benchmarks.
This is a deliberately asymmetric comparison. From the start we were not aiming to improve performance; we wanted to make a better alternative to context window compaction via summarization and unlock a capability of "infinite" context window with no performance degradation.
Across all four benchmarks, CWL vs. baseline differ by at most three percentage points in either direction, well within run-to-run variance: Terminal Bench 2.0 68.25% vs 68.40%, SWE Bench Lite 43.00% vs 40.00%, Recovery Bench 66.80% vs 69.75%, LongCLI Bench 20.00% vs 20.00%. The principal result is parity, achieved under a substantially harder regime.
What's left
We observed behavioral changes in the model that we couldn't conclusively attribute to CWL. In some sessions the model rushed exploration with less thoroughness than it showed without CWL; in longer sessions it occasionally over-explored, revisiting already-annotated material or looping over actions without apparent progress. These behaviors overlap with ordinary planning failures, and we couldn't isolate CWL as the cause in individual cases. More precise prompting mostly resolved it. Our tentative read is that the annotation protocol introduces a layer of meta-reasoning the model has to do alongside the task, and that this is mildly confusing for current models. If that's right, the effect should diminish as model capability improves.
The current design assumes a linear stream of episodes with non-linearity expressed only through dependency edges. Whether richer structure (subgraphs, subtask roots) is needed for agents that branch, backtrack, or run parallel subtasks is open.
Where this goes
CWL is a working system, not a research artifact. The implementation is open source as a fork of pi.dev: github.com/Kiz8-Team/pi-cwl. The full paper has the architecture, the empirical setup, and the design principles in detail.
If you're working on this and want to compare notes, we'd be glad to; please reach out to ands@kiz8.team
Kiz8 — 2026
/ revisions
- Published · 14 May 2026
- CC BY 4.0